目标
对这个 网页中的数据集进行数据处理,选择一列 找出最大值和最小值, 选择其中两列求出差值并求和.
步骤
对于html, 可以使用wget或curl读入. 处理html内容可以采用pup工具来实现.
下载网页到本地
wget https://stats.wikimedia.org/EN/TablesWikipediaZZ.htm -O pra.html
对网站元素进行查看
最好的方法是使用浏览器的审查元素方式进行查看, 能够较快的找到自己所需的内容.
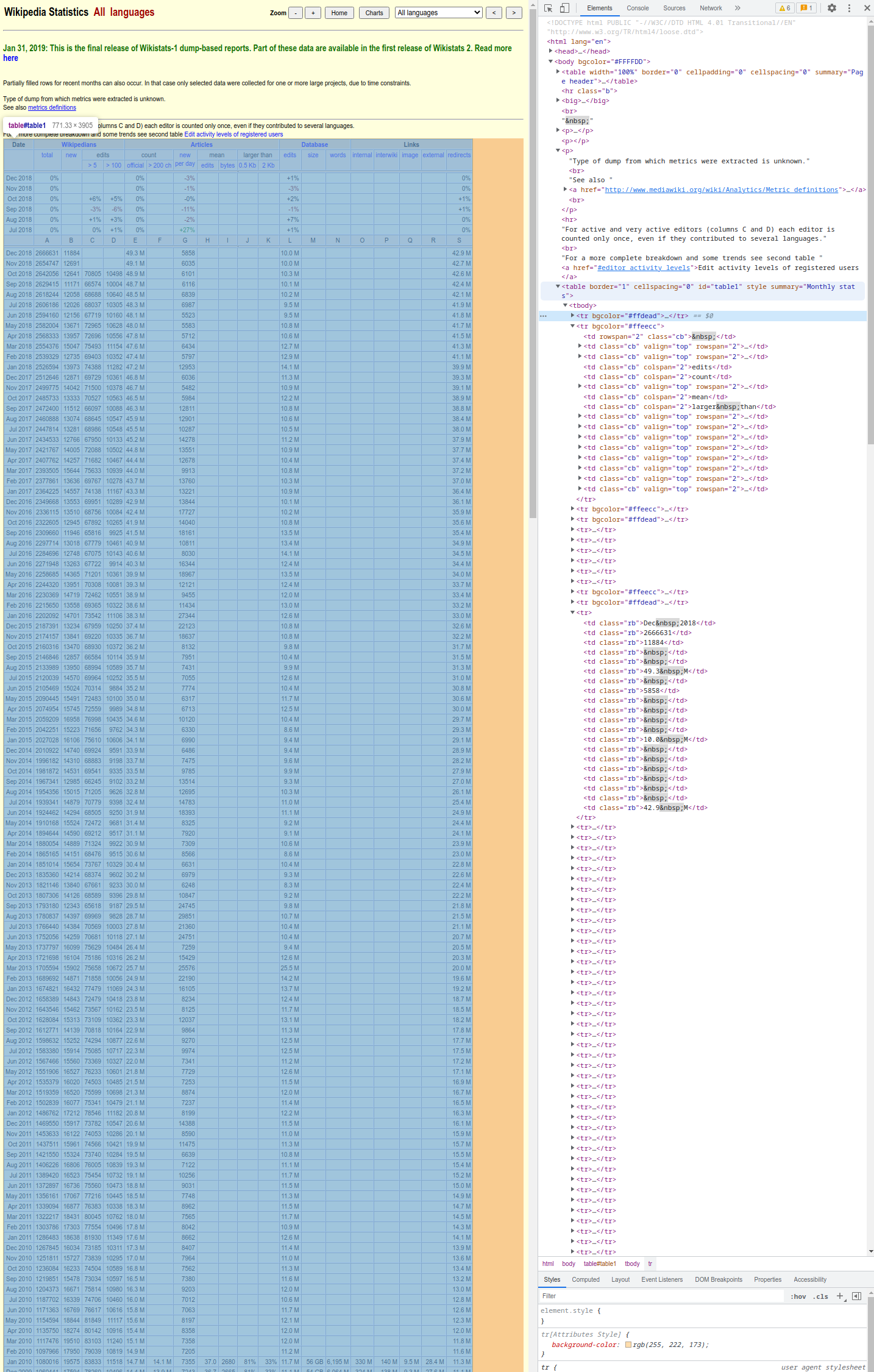
可以看到我们所需的数据表格在table中,id为table1.更近一步观察可以看到位于tbody中.可以通过pup过滤并 输出内容.
数据处理
通过pup获取html中第一个表格的数据
cat pra.html | pup 'table#table1 tbody td next{}'
此时内容如图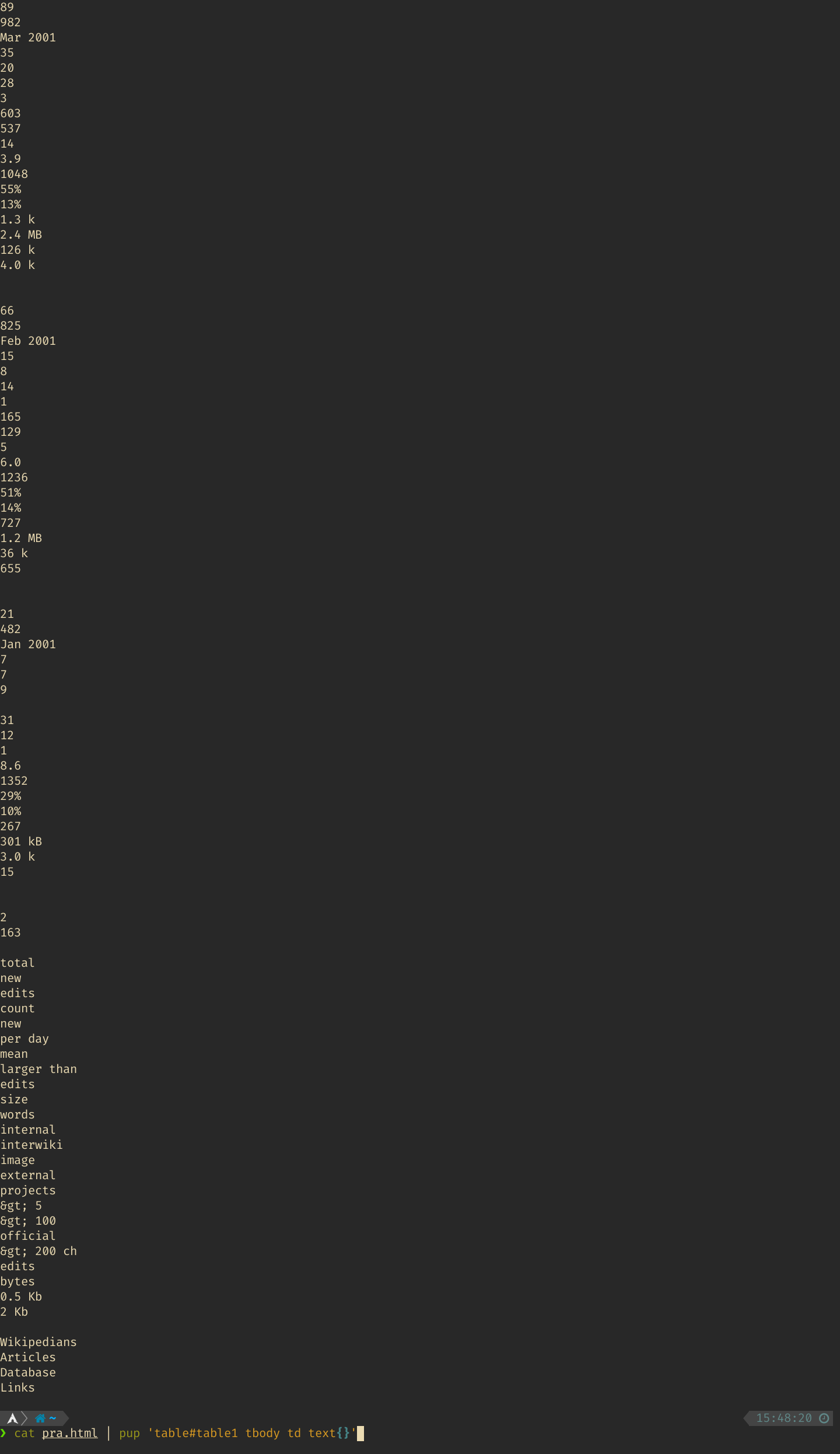
去除头部和尾部部分行
对于表格文件,我只关心表格中间的数据,而忽略表头和表尾,这里采用head和tail进行过滤.
删除尾部30行,删除头部208(209-1)行.
head -n -30
tail -n +209
将列变为行,以空格分割
相对于一列,我更喜欢处理以整行数据,这样就可以利用awk的$获取分割.
通过tr命令进行替换
tr '\n' ' '
awk
awk是一种善于处理文本的编程语言,他太强大了,以至于我们可以用awk完成其余的所有操作.
awk '{sum = 0;max = 0; min = 65536;for(i = 2;i < 4302; i+=20) {if(max < $i) max = $i; if(min > $i) \
min = $i; if($i > $(i+1)) sum += $i - $(i+1); if($i <= $(i+1)) sum += $(i+1) - $i;}print max; print \
min; print sum }
正如我们所说,awk是一种编程语言,代码块中,$0 表示整行的内容,$1 到 $n 为一行中的 n 个区域,区域的 分割基于 awk 的域分隔符(默认是空格,可以通过-F来修改)。
这里一个有趣的是,由于awk本来是以空格分割,而对于1.2 Mb,我以为他也会被分割,导致我无法获取正确的结果. 但情况是分割正确.通过分析发现这中间的空格并不是我们通常的ASCII 32.还有一个特殊的空格是ASCII 160. 是 产生的空格
通过awk,我可以完成之后的全部操作.
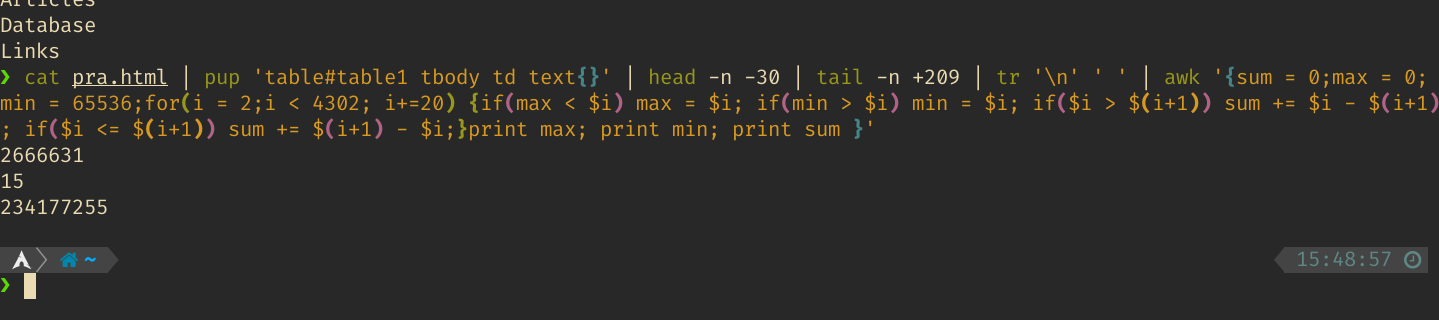
至此我们获得了一个特别长的命令行操作,他们之间由pipe处理
cat pra.html | pup 'table#table1 tbody td text{}' | head -n -30 | tail -n +209 | tr '\n' ' ' | awk \
'{sum = 0;max = 0; min = 65536;for(i = 2;i < 4320; i+=20) {if(max < $i) max = $i; if(min > $i) min \
= $i; if($i > $(i+1)) sum += $i - $(i+1); if($i <= $(i+1)) sum += $(i+1) - $i;}print max; print min\
; print sum }'
最后结果如下
总结
通过命令行进行数据处理需要多种工具相互结合.其中比较常用的有tr,sed,awk,sort,head,tail等.
正则表达式很有用,虽然这道练习只用到了替换.
你不能期待一个操作解决全部问题,通过管道,你可以将问题拆分为多个小问题并利用多个工具完成操作.