NUMA 深度探索:从UMA到NUMA (翻译及总结)
原文连接:numa-deep-dive-part-1-uma-numa
引言
非一致存储访问(NUMA)是一种在现今多处理器系统中使用的共享内存架构。每个CPU被分配了自己的本地内存,同时可以访问系统中其他CPU的内存。访问本地内存提供了低延时-高带宽的性能。而访问其他CPU的拥有的内存则具有较高的延时和较低的带宽。
现代的应用与操作系统(如ESXi)默认支持NUMA,但为了提供最佳性能,应该考虑在使用NUMA时进行虚拟机配置。不正确的设计可能会导致特定虚拟机,乃至运行在ESXi主机所有虚拟机出现性能不一致或整体性能降低的情况。
这个系列旨在介绍CPU架构,内存子系统以及ESXi系统对CPU及内存的调度策略。让你能够创建一个高性能的平台,为高质量服务和更高的整合率奠定基础。在我们讨论现代计算机架构之前,我们想先复习一下共享内存多处理器的历史,这能让我们更好理解今天为什么要使用NUMA系统。
共享内存多处理器架构的演变
我们往往认为一致内存访问的方式更适合低延迟、高带宽的架构,但现在的计算机系统架构限制了它的实现。我们可以通过回顾历史找到并行计算的关键驱动力来找到原因。
在七十年代引入的关系型数据库使得能够提供多用户并发操作与过度数据生成的系统需求变成了主流。尽管单处理器的性能提升已经很耀眼,但多处理器系统能够更好的满足工作负载。为了提供性价比高的系统,共享内存地址空间成为了研究的重点。
注: 毫无疑问通过共享内存地址可以解决很多成本
早期系统使用交叉开关的方式实现共享内存,然而这种设计的复杂性随着处理器核心的增长而增加,使得基于总线的系统在现今更加流行。是提供更多内存可用性的一种非常有性价比的方式。这提供了更多的内存可用性,同时具有很好的性价比。
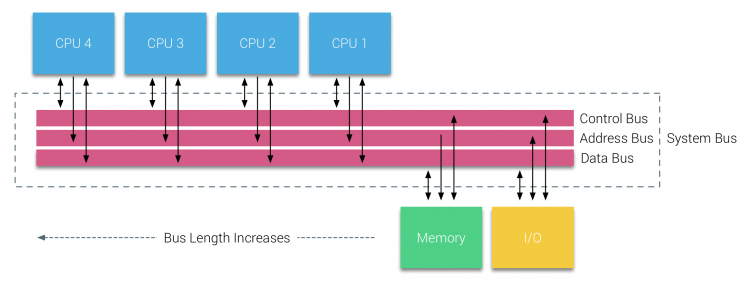
但是基于总线的系统也带来了可扩展性问题。最大的问题是带宽的限制,这限制了总线容载处理器的数量。将CPU添加到系统中需要考虑两个主要问题:
- 当一个CPU被添加时,对每个节点带来的带宽下降。
- 当添加更多处理器时导致总线长度提升,这会带来更高的延迟
CPU性能的增长,尤其是处理器与内存间的速度剪刀差,在过去和现在都严重制约着多处理器。现今处理器与内存间的速度剪刀差增长态势明显,因此如何高效管理内存系统一直是相关研究的重点。其中的一种策略是通过缓存,但这也带来了很多挑战。这些挑战仍是目前CPU设计者要考虑的重点,比如对缓存结构和替换算法的研究,以避免缓存失效。
缓存监测协议
为每个CPU添加上缓存能够很好的提升性能。一方面更加靠近CPU的内存缩短了CPU的访存时间,另一方面直接访问缓存可以降低总线的带宽负载。
共享内存架构中为每个CPU添加cache的主要挑战在于如何允许内存块的多个备份存在。这被称为缓存一致性问题。
缓存监测协议创建了一个不消耗全部总线资源但能提供正确数据的模型。其中最受欢迎的是写无效协议的引入。CPU在写入本地缓存之前会擦除所有缓存的数据备份,使得随后其他CPU对响应数据在缓存中的访问都会失效,再由最近修改数据的CPU本地缓存中提供相应的数据。
这种模型节省了大量的总线带宽,同时也使得一致内存访问系统在九十年代初期得以出现。我们将在第三部分介绍现代缓存一致性的更多细节。
一致存储访问架构
一致存储访问架构(UMA),又被叫做对称多处理器(SMPs),指的是基于总线的多处理器上,每个处理器的访存行为及访问延迟都是一致的。
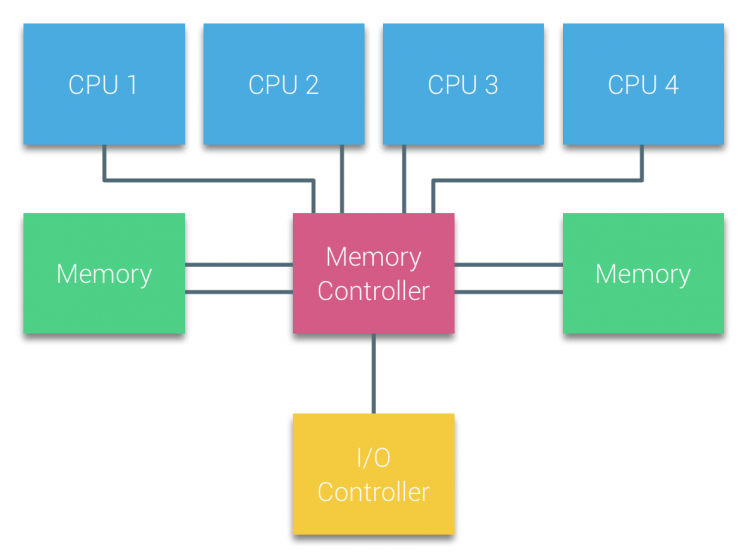
在UMA系统中,CPU通过系统总线连接到北桥,北桥包含了内存控制器,所有的与内存相关的访问都需要经过北桥。负责管理I/O设备的I/O控制器也连接到北桥上。因此每个I/O信号也需要经过北桥连接到CPU。
通过添加多个总线和内存通道可以增加北桥的带宽以此消除北桥带来的瓶颈问题。在某些系统中还可以将外部内存控制器添加到北桥上来提高内存带宽,同时增加更多内存支持。但缓存监测协议的广播性质导致UMA的可扩展性受到限制。因此UMA架构无法满足未来的负载需求(现在的高速闪存设备每秒已经要处理成百上千的I/O请求)。
注:越多的I/O访问意味着处理器间的缓存监测协议实现越复杂。
非一致内存访问架构
为了提升共享内存多处理器架构的可扩展性和性能,可以考虑三个关键的点:
- 非一致内存访问
- 点到点的内连拓扑
- 可扩展的缓存一致性解决
1.非一致内存访问
NUMA不再使用内存池而是引入了拓扑属性,根据处理器到内存的路径长度进行分类以避免内存访问延迟和带宽瓶颈的问题。实现NUMA需要对处理器系统和芯片架构进行重设计。九十年代末的SGI超级计算机对NUMA架构的引入使得NUMA开始受到关注。NUMA帮助识别内存的位置,在这种系统中需要确定哪个机箱中存储了特定(需要的)内存。
在世纪初,AMD将NUMA引入到UMA系统统治的商业区域。在2003年AMD Opteron 系列出现,其集成的内存控制器下每个CPU都有属于自己的内存库。每个CPU也有属于自己的内存空间。NUMA的操作系统,例如ESXi能够允许工作负载在多个地址空间上(本地和远程),同时也可以优化内存访问。我们用带着两个CPU的系统来介绍本地内存访问和远程内存访问的区别。
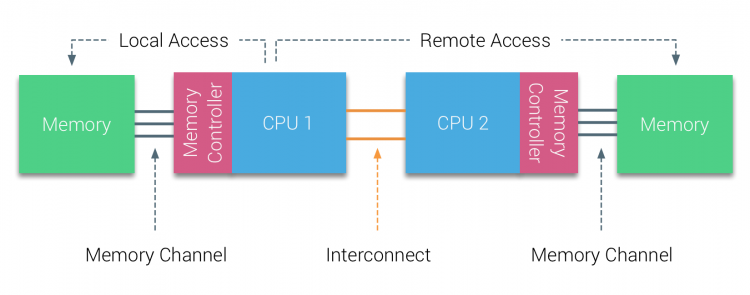
连接在CPU1上的内存被看作是本地内存,而连在其他CPU上的内存(这里是CPU2)被认为是远程内存。远程内存由于需要跨越互联接口连接到内存控制器而具有比本地内存更高的延迟。对于系统架构而言,不同的内存有着不同的位置,造成了“非一致”的访存时间。
2.点对点互联
AMD 在AMD Opteron 微架构中引入了点对点互联的 HyperTransport。而因特尔在2007年放弃了他们的双独立总线架构,在他们的Nehalem架构中开始使用QuickPath Architecture。
Nehalem architecture 被认为是因特尔微架构中的一个重大改变,同时也被认为是真正第一代酷睿系列。目前的Broadwell架构是因特尔酷睿系列的第四代(Intel Xeon E5 v5)。最后一张图片中展示了更多关于因特尔微架构世代的信息。在QuickPath 架构中,内存控制器进入到每个CPU核中,同时在系统中引入了点对点的快速互联路径(QPI)作为CPU在系统中的数据连接。
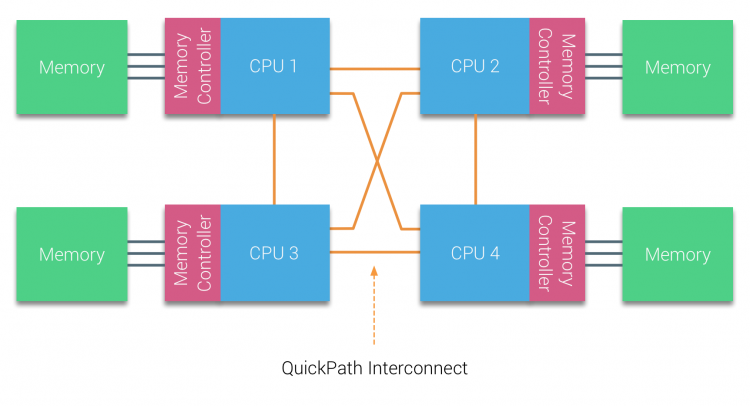
Nehalem 微架构不仅替代了前端总线,还重新组织了服务器处理器的子系统,使之模块化。这种模块化设计被叫做“Uncore”,同时创建了对缓存和互联速度的设计的构建库。移除前端总线也改善了带宽的可扩展性问题,但当内存容量过大时也需要考虑处理器核间的传输带宽问题。
集成内存控制器和QuickPath 互联都是Uncore的一部分,可以通过模型特定寄存器(MSR)进行访问。它们连接到MSR上,提供了处理器核间内部通信的功能。Uncore的模块化还可以为因特尔提供不同的QPI速度,在目前(2016)因特尔的Broadwell-EP 微架构提供了6.4GT/s,8.0GT/s和9.6GT/s的速度。在CPU之间提供了理论最大带宽为25.6GB/s,,32GB/s和38.4GB/s。为了对比,最新前端总线提供了1.6Gt/s和12.8GB/s的平台带宽。
在推出Sandy Bridge处理器时,英特尔将Uncore重新命名为System Agent,但是Uncore这个术语仍然在当前的文档中使用。在第二部分中,您可以了解更多关于QuickPath和Uncore的信息。
可扩展的缓存一致性
处理器核到L3 cache间提供了一条由上百条线组成的私有通道。这种情况下缩小纳米制造工艺的同时增加处理器核数量需要复杂的设计工作,因此这种架构可扩展性很差。为了增强扩展性,Sandy Bridge 架构通过将L3 cache 移除Uncore 部分并引入可扩展的环形芯片互联架构来增强了可扩展性。依靠此,因特尔可以将L3 cache 以切片的方式进行分区和分发来提供更高的带宽和更高的关联性。每个切片提供了2.5MB的大小,同时关联到核心上。环形互联也允许每个处理器核心访问每一个切片。以下是Broadwell微架构(v4)(2016)的低核心计数(LCC)至强CPU的模具配置。
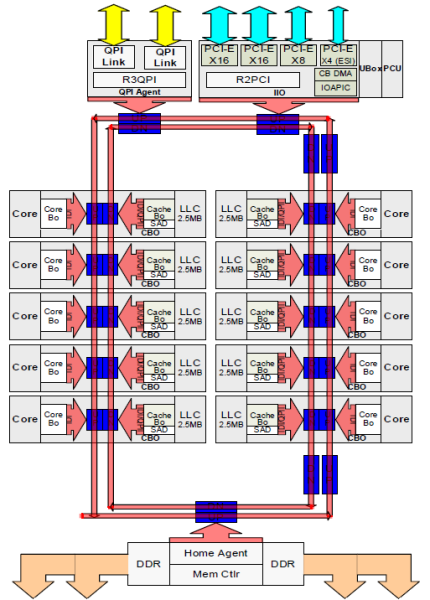
这种缓存架构需要提供在本地的分布式缓存与其他核心间的监测协议来确保缓存一致性。随着处理器核的增加,缓存缺失的频率也会增加,因此监测协议的流量也随之增长。这意味着QPI和最后级别缓存(LLC)的消耗会增加,因此需要持续开发嗅探协议以提高维护缓存一致性的效率。
第三部分将更加深入介绍Uncore,可扩展的片上环形总线和缓存嗅探协议的重要性。
节点交错的NUMA:SUMA
物理内存在主板上被分配,但系统可以通过交错内存的方式为两个NUMA节点提供单一的地址空间。这被叫做节点交错(在第二部分介绍)。当节点交错使能时,系统便成为了充分的一致访存架构(SUMA)。不再将处理器和内存的信息交给操作系统,而是将内存分割成4KB的小地址区域并且轮询映射到每个节点上。提供了一种“交错”的内存映射来让内存分布式的映射到这些节点上。
当ESXi分配内存给虚拟机时,例如从两个不同的节点分配物理内存,当节点0需要拉取节点1的内存时,这些内存会通过QPI通道连接。
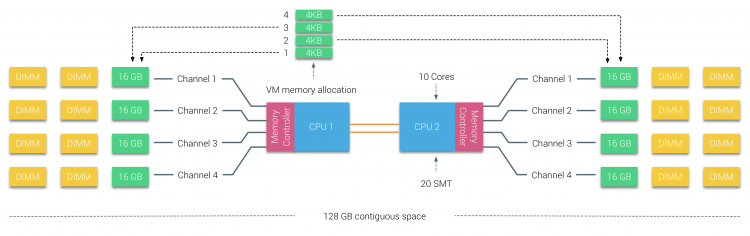
对于SUMA而言最有趣的便是它能提供了一致的内存访问时间。但不是最优化的,而且很大程度依赖于QPI架构中竞争的水平。Intel 内存延迟检测工具被用来展示统一系统中使用NUMA和SUMA的区别。该测试测量从系统中每个socket到另一个socket的空闲延迟(以纳秒为单位)。socket 0 到 内存节点0的是本地内存访问, socket0 到内存节点1是远程内存访问。系统配置为NUMA的情况下。
注:这里的socket指处理器插槽,memory node指内存节点,在NUMA架构中,每个处理器插槽都有自己的内存节点。
注:引用评论的解释,在SUMA的情况下会对内存地址空间进行交错重排,虽然此时系统仍认为是NUMA的访问,但其实没经过一个单元的地址空间就会切换到另一个节点。而对于NUMA下的访问延迟平均为75.7 + 132.0 = 207.7 / 2 == 103.85,非常接近SUMA下的访问延迟。
正如预料,交错访问受到QPI链路的影响。空闲内存状态下的测试有着最好的结果。但我们更需要的是负载下的测试,毕竟你的ESXi服务不能白白耗电用。负载延迟测试能够让你更好的看到在自然负载情况下的系统延迟。测试每两秒更改以此系统注入延迟,并在此级别测量带宽和响应的延迟。测试使用百分百的读取流量,NUMA测试结果在左侧,SUMA测试结果在右侧。
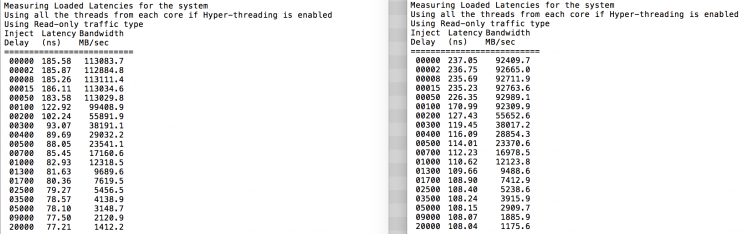
从报告可以看出,SUMA具有更低的带宽和更高的延迟。因此我们应该优化虚拟机的大小以更好的适应NUMA系统的特性。
总结
由于对多处理器的需求产生了共享内存多处理器架构,UMA(一致性存储访问)实现相对简单,同时对操作系统调度要求不高(只需要进行内存访问),率先走入商业市场。但UMA也带来了可扩展性问题和带宽瓶颈(高延迟,低带宽问题)。
一个解决方案是添加缓存,但这同样带来了在多处理器核心下的缓存一致性问题,这里引入了第一个重要的概念:缓存嗅探协议(cacheing snoop protocols)
NUMA(非一致性存储访问架构)通过为每个处理器核心添加本地内存实现了处理器核心对本地内存的低延时,高带宽的访问。为了实现处理器核间的访问,提出了内连机制,其中最著名的应该是QPI(QuickPath Interconnect),由因特尔提出。
因特尔的Nehalem 架构利用QPI替代了前端总线,重新组织了服务器处理器架构的子系统,被叫做Uncore。没懂
缓存一致性的问题依旧是需要解决的问题,我们很难为每一个处理器核的添加都添加相应的cache(实在太复杂了),因此提出了环形芯片互联架构,通过切片的方式分配缓存。当然,一致性嗅探协议还是要的。
SUMA通过交错的方式重新编织了NUMA,使得系统会看到整块的内存空间(逻辑上)而不是分离的(NUMA是分离的)。但是会带来一些性能上的问题存在。因此如果可以,还是希望我们的虚拟机能够更好适应NUMA系统的特性。
可以看到架构的演变,从互联开关到总线,再到如今的QPI(但谁又知道过去的架构会不会哪一天在新的地方回归呢)。